LRZ-Newsletter Nr. 11/2019 vom 14.11.2019

Diesen Newsletter finden Sie auch auf Englisch auf der Website des Leibniz-Rechenzentrums
Unsere Themen:
- Aktuelles
- Termine, Kurse und Veranstaltungen
- Technik: Gebrauchtes zu Verschenken
- Stellenangebote / Job Opportunities
- Mehr Lesestoff
- Informationen zum LRZ-Newsletter
- Impressum
Aktuelles

Bayerns Exporte fürs Supercomputing
Aufkleber und Taschen sind bedruckt, der MaiMUC, ein Maibaum aus zehn scheckkarten-großen Raspberry Pi-Computern, wird an der Technischen Universität München (TUM) gerade verpackt, die letzten Paper und Poster sind in Vorbereitung: Ende der Woche beginnt in Denver die SC19. Das Leibniz-Rechenzentrum (LRZ) hat die Bayerische Supercomputing Alliance (BSA) ins Leben gerufen und startet mit Vertretern aus fünf bayerischen Universitäten und Rechenzentren zur weltweit führenden Leitmesse für das High Performing Computing (HPC).
In Vorträgen und Diskussionen treten 21 Teilnehmende in den USA den Beweis an, dass aus Bayern viele Ideen und Tools für Supercomputer exportiert werden: "Von Energieffizienz über Monitoring bis hin zu Künstlicher Intelligenz besetzen wir im Team wichtige Themen und liefern praktische Lösungen", sagt Professor Dieter Kranzmüller, Leiter des LRZ. Neben Bayerns größtem Rechenzentrum sind während der SC19 am Stand 2063 auch die Ludwig-Maximilians-Universität (LMU), die TUM, die Friedrich-Alexander-Universität (FAU), das regionale Rechenzentrum Erlangen (RRZE) sowie die Universität Regensburg und die technische Hochschule Deggendorf im BSA-Team vertreten.
Nützliche Tools fürs Supercomputing
Am weiß-blau gestalteten Messestand 2063 wird nicht nur der TUM-MaiMUC Besucher anziehen. Der Maibaum aus Mini-Computern ist ein hübsch bayerisches Ausstellungsstück und verkörpert zugleich einen Multicore-Computer. Ausgerüstet mit LED-Bildschirmchen, einem Intel Movidus USB-Stick für Machine Learning sowie Kameras wird der MaiMUC die Besucherzahlen und -Vorlieben am Stand auswerten: Künstliche Intelligenz und Mustererkennung im Kleinformat. Neben Forschungsergebnissen zu Leistungen neuer Schnittstellen fürs HPC oder zum Einsatz von künstlicher Intelligenz befinden sich im Gepäck der BSA außerdem die Tools Data Center Data Base (DCDB) sowie LIKWID aus Erlangen, mit denen Rechenzentren die Auslastung ihrer Computer verbessern und Wissenschaftler Anwendungen besser anpassen können.
Sehenswertes aus dem All
Eines der Highlights sind sicher die sensationellen Bilder aus dem All, mit denen die Astrophysiker Salvatore Cielo und Luigi Iapichino zusammen mit dem Visualisierungsteam des LRZ die Geburt von Sternen veranschaulichen. Der einzigartige Drei-Minuten-Film tritt im Wettbewerb um die besten sechs Visualisierungen im HPC an. Noch mehr bayerische Präsenz in den SC-Wettbewerben: Arndt Bode, langjähriger Leiter des LRZ und emeritierter Informatik-Professor der TUM, ist 2019 Vorsitzender der Jury des berühmten Gordon Bell Preises, der herausragende Forschungsarbeiten im HPC kürt.
Ausgezeichneter HPC-Nachwuchs aus Bayern
Nicht zuletzt werden Lehr-Anforderungen in Denver am BSA-Stand diskutiert. Sechs Doktoranden der FAU aus Erlangen nehmen am Studentenwettbewerb teil. Team „DeFAUlt“ wird in Denver nicht nur praktische HPC-Aufgaben lösen, sondern auch eine Vortragsreihe rund um das Supercomputing vorstellen. Mehr über die BSA und über die SC19 in Denver erfahren Sie auf der neuen Website www.bavariansupercomputing.de, die demnächst online geht. (vs)
Mehr Lizenzen, mehr Rechenkraft
Die Software von ANSYS ist schon seit Jahren am Leibniz-Rechenzentrum (LRZ) im Einsatz: Auf dem alten SuperMUC war sie auf rund 3500 Rechenkerne limitiert, für den neuen SuperMUC-NG wurde die Zahl der Lizenzen erweitert. Mit Unterstützung des Grafinger Dienstleisters CADFEM läuft die Simulationssoftware nun auf mehr als 18.000 Rechenkernen: "Wir konnten unseren Lizenzbestand mehr als vervierfachen, so dass jetzt entweder mehr Nutzer gleichzeitig damit arbeiten oder deutlich größere Problemstellungen aus den Bereichen Numerische Strömungsmechanik und Strukturmechanik gelöst werden können", erklärt Thomas Frank, habilitierter Strömungsmechanik-Ingenieur und Experte für High Performance Computing (HPC) am LRZ in Garching.
Strömungen simulieren
ANSYS ist eigentlich ein Paket aus rund 20 Programmen und Anwendungen, mit denen Ingenieure und Wissenschaftler komplexe technische Fragen und Technologien am Computer simulieren und analysieren. Im HPC und am LRZ werden von ANSYS vor allem die Anwendungen stark CFX und Fluent genutzt. Sie kommen dann zum Einsatz, wenn die Strömungseigenschaften von Gasen, Flüssigkeiten, Fluid-Gemischen und Mehrphasenströmungen zwei- oder dreidimensional dargestellt werden sollen, etwa um die Konstruktion von Turbinen zu beurteilen, neue Raketenantriebe zu entwickeln oder die Aerodynamik von Fahrzeugen zu verbessern. Das Bild wurde mit ANSYS gefertigt und zeigt Luftverwirbelungen an einem Automodell.
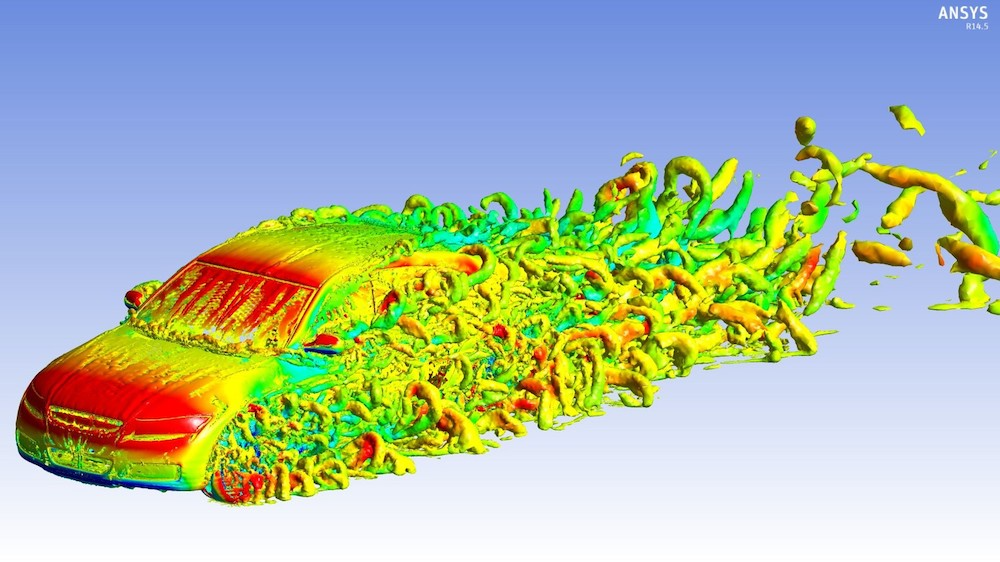
Vielfach im Einsatz
Am LRZ gehört ANSYS zu den meist genutzten kommerziellen Softwareprogrammen. Mehr als ein Viertel der Rechnerstunden des SuperMUC entfielen in den letzten sechs Jahren auf die Strömungsmechanik, also die Computational Fluid Dynamics (CFD). ANSYS wird etwa alle vier Monate aktualisiert, zuletzt im September 2019. (vs)
"Erfahrungen und erste Ansatzpunkte zum Stromsparen in Rechenzentren"

Strom sparen mit Daten: Etwa fünf Megawatt Strom verbraucht das Leibniz-Rechenzentrum (LRZ), bis zu vier davon fließen in den SuperMUC-NG. Damit sie möglichst effizient verwendet werden und der Verbrauch künftig sogar sinkt, setzt das LRZ bereits auf ein innovatives Kühlungssystem mit Warmwasser und forscht nach noch mehr Möglichkeiten, Strom zu sparen. Daten aus den Rechnersystemen und aus den Programmen könnten helfen, die Arbeit der Maschinen effizienter zu organisieren: Über die Strategien, die Energieeffizienz von Hochleistungscomputern und Rechenzentren zu steigern ist jetzt ein Buch erschienen, in das Erfahrungen aus dem LRZ einflossen. Am 12. Dezember 2019 ist Herausgeber Luigi Brochard zu Gast am LRZ, um diese zu diskutieren. Ein Gespräch mit Michael Ott vom LRZ über energieeffiziente Hochleistungs-Computer:
Warum ist der Energieverbrauch von Rechenzentren ein Thema für Forschung & Entwicklung – und außerdem für ein Buch?
Dr. Michael Ott: Weil Computer und insbesondere Rechneranlagen viel Strom verbrauchen. Auch Rechenzentren wollen ihren Beitrag zu Nachhaltigkeit und Ressourcen-Schonung beitragen. Hersteller oder wirtschaftlich betriebene Rechenzentren sind aber meist in so enge Prozesse eingebunden, dass ihnen die Zeit zum Experimentieren fehlt. Das Interesse an Energieeffizienz ist aber hoch, das zeigt auch das Buch "Energy -Efficient Computing and Data Centers". Es entstand auf Initiative von Luigi Brochard, einem ehemaligen Mitarbeiter von IBM und Lenovo, der sich für Energieeffizienz interessiert und in Zusammenarbeit mit verschiedenen Wissenschaftlern Erfahrungen und erste Ansatzpunkte zum Stromsparen in Rechenzentren zusammengetragen hat.
Wer soll das Buch lesen und warum?
Ott: Computer-Hersteller finden darin sicher Anregung, aber auch die Betreiber von Rechenzentren, und sicher interessieren sich viele Informatiker und Daten- Spezialisten dafür, wenn sie sich klarmachen, dass ihre Arbeit am Computer eben viel Strom verbraucht.
Sie leiten innerhalb der internationalen Energy Efficient HPC Working Group das Team für Datenanalyse und arbeiten an Lösungen zur Senkung des Stromverbrauchs in Rechenzentren.
Ott: Mit der Arbeitsgruppe erforschen wir alle Betriebsparameter für Hochleistungs-Rechenzentren. Kurz gesagt geht es darum, überall in Rechenzentren Daten zu erfassen, zu analysieren und danach Arbeitsweisen und Systeme anzupassen, um die Energieeffizienz zu steigern. Am LRZ haben wir dazu ein Open-Source-Monitoring-Tool entwickelt: Data Center Data Base oder DCDB erfasst Daten aus unterschiedlichsten Quellen, die wir bald auswerten und mit denen wir hoffentlich die Systeme optimieren können. Der nächste Schritt wird dann sein, solche Daten durch Künstliche Intelligenz auszuwerten zu lassen, um später die Systemanpassung zu automatisieren.
Supercomputer wie der SuperMUC-NG des Leibniz-Rechenzentrums verbrauchen in Hochzeiten 3,4 Megawatt – wo können Sie ansetzen, um den Stromverbrauch zu senken?
Ott: Technisch sind die Systeme ausgereizt, Prozessoren und Rechnerkerne arbeiten bereits sparsam und für ihre Kühlung, einer der größten Energiefresser, gibt es ebenfalls schon sehr gute Lösungen. Am LRZ arbeiten wir mit einem Adsorptions-System, mit dem sich die Abwärme von SuperMUC-NG zur Klimatisierung des Rechenzentrums nutzen lässt. Noch aber passiert zu wenig mit den Programmen. Werden Applikationen besser an die Rechner und ihre Leistungen angepasst, sinkt deren Stromverbrauch. Erste Tools wie „Energy Aware Runtime“ (EAR) regeln beispielsweise die Taktraten herunter, wenn diese nicht vollständig gebraucht werden. Denkbar wäre auch, Rechenaufträge besser zu organisieren und aufeinander abzustimmen um deren Durchsatz zu erhöhen. Dafür erwarten wir noch viele Anregungen durch das Monitoring und durch DCDB.
Gibt’s schon erste Erkenntnisse aus dem Open-Source-Programm Data Center Data Base?
Ott: Wir sind gerade damit beschäftigt, das Monitoring-Programm auf dem SuperMUC-NG zu installieren und es auf Kongressen wie der ISC in Frankfurt oder demnächst auf der SC2019 in Denver bekannt zu machen, um mehr Anwender zu gewinnen. (Interview: vs)
FAIRe Forschungsdaten
Informationen auffindbar, sichtbar und nutzbar machen: Das war eines der zentralen Themen des Open Search-Symposiums, das Ende Oktober am Leibniz-Rechenzentrum (LRZ) unter der Ägide der Open Search Foundation stattfand. Vor allem Wissenschaftsdaten sollten FAIR sein, also findable (auffindbar), accessable (zugänglich), interoperable (interoperabel) und reusable (nutzbar). Das LRZ beschäftigt sich dafür mit mehreren Projekten, deren Ziel unter anderem der Aufbau eines Management-Systems für Forschungsdaten ist: "Unser Fokus liegt darauf, Daten aus dem High Performing Computing FAIR zu machen. Datensätze aus Supercomputern umfassen oft mehrere hundert Terabyte Information, sind daher eher unbeweglich und können auch nicht in klassischen Repositorien hinterlegt werden", erklärt der promovierte Physiker Stephan Hachinger das Grundproblem. "So entstehen Silos, deren Daten weder ausgetauscht, noch weiter genutzt werden können." Dabei finden sich in ihnen Informationen, die für andere Projekte von großem Nutzen sein könnten.

Ein Management-System für Forschungsdaten
Das "Research Data Management Team" des LRZ arbeitet dafür gerade am Aufbau eines Systems, mit dem Forschungsdaten aus diversen LRZ-Systemen, etwa dem SuperMUC-NG, auffindbar werden: "Dafür statten wir Datensätze mit Metadaten wie Titel, Autoren, Schlagwörter aus, um sie für Suchmaschinen aufzubereiten", erklärt Alexander Götz. Die so entstehenden Informationen bekommen außerdem eine Identifikationsnummer, den Digital Object Identifier (DOI), der wie eine ISBN-Nummer in Büchern zu einzelnen Titeln oder eben Datensätzen führt. Die zum DOI gehörenden Informationen sammeln sich idealerweise noch auf einer Webseite und bieten den Link zum Datensatz. Und natürlich sollten sie mit Hilfe von Schnittstellen auch maschinenlesbar und damit von Suchmaschinen eingesammelt werden können. Suchportal-Projekte wie EUDAT-B2FIND auf europäischer oder Generic Research Data Infrastructure (GeRDI) auf nationaler Ebene nutzen bereits diese Techniken, bei GeRDI waren das Research Data Management-Team und das LRZ aktiv beteiligt.
Container, Services und Schnittstellen zum Datenaustausch
Was sich einfach anhört, braucht technischen Aufwand: Erst mit der Cloud, Containern sowie Microservice-basierten Architekturen ist es möglich, ein System auszubauen, das zum einen flexibel und zum anderen leistungsfähig genug ist, um den Anforderungen von Supercomputern und Speichersystemen am LRZ gerecht zu werden. "Damit stehen wir erst am Anfang", sagt Hachinger. "Aber wir hoffen, dass wir aus dem Research Data Management-System weitere Services für das LRZ und seine Forschungsklientel ableiten können."
Auch LEXIS, ein EU-Projekt mit LRZ-Beteiligung, das sich mit Workflows von Supercomputern innerhalb von Cloud-Systemen beschäftigt, arbeitet an der Zugänglichkeit großer Datensätze: Dabei steht neben dem Ziel der FAIRness ein System zur verteilten Datenhaltung im Mittelpunkt, und zwar auf Basis von EUDAT-B2SAFE. Diese „Distributed Data Infrastructure“ soll unabhängig vom Speicherplatz und von der abrufenden Institution den einheitlichen Zugriff auf Daten aller beteiligten europäischen Rechenzentren bieten. Der aktuelle Stand dieser Bemühungen sowie zum Research Data Management-System des LRZ wurden am Open-Search-Symposium in Postern und Talks präsentiert.
Einheitlichkeit gefordert
"Die heute in Datenrepositorien schlummernden Erkenntnisse könnten in Zukunft wesentlich besser genutzt werden, wenn es einheitliche Schnittstellen und Protokolle für den Zugang gibt", ist sich Götz sicher. Wie diese aussehen könnte, damit wird sich bald auch die Research Data Alliance (RDA) beschäftigen: Zusammen mit Experten des amerikanischen National Institute of Standards and Technology (NIST) haben die Datenspezialisten des LRZ auf dem diesjährigen RDA 14th Plenary in Helsinki Ende Oktober Ideen und weitere Aufgaben für Teams vorgestellt. (vs)
Tsunami-Rätsel gelöst
Digitale Simulationen helfen, die Welt zu begreifen: Einem internationalen Team aus Wissenschaftlern um die Münchner Geophysikerin Dr. Alice-Agnes Gabriel und den Doktoranden Thomas Ulrich ist es gelungen, am Leibniz-Rechenzentrum (LRZ) in Garching das Rätsel um den Tsunami von Sulawesi 2018 zu lösen. Nicht wie vermutet die Erdrutsche am steilen Ufer der Palu Bay, sondern äußerst schnelle Reißbewegungen des Meeresbodens sowie die spezielle Tektonik der Bucht lösten den rätselhaften Tsunami aus: "Wie in einer Badewanne muss sich die dadurch ausgelöste Flutwelle in der engen Bucht aufgetürmt haben", erklärt Gabriel bahnbrechende Forschungsergebnisse, von denen inzwischen oft berichtet und die viel diskutiert werden.
Eine Katastrophe überrascht die Forschung
Im September 2018 erschütterte erst ein Erdbeben die Region Sulawesi von Indonesien, danach folgte eine Flutwelle in der schmalen, lang gezogenen Palu Bay an der Westküste. 4000 Menschen starben durch die Katastrophe, 14.000 wurden verletzt. Erdbeben sind eigentlich nichts Ungewöhnliches in dieser Gegend, aber keiner konnte sich den folgenden, schweren Tsunami erklären. Gewöhnlich entstehen Flutwellen nach vertikalen Verwerfungen der Erde, nicht aber nach horizontalen Erdbewegungen wie sie in Sulawesi beobachtet worden waren.
Gekoppelte Simulation legen eine Spur
Für die Erkundung des Tsunamis in Palu wertete das Team um Gabriel und Ulrich, beide forschen und lehren an der Ludwig-Maximilians-Universität München, nicht nur Daten vergleichbarer Katastrophen aus, es kombinierte außerdem unterschiedliche Simulationen von Erdbeben und Tsunamis miteinander und fand in den so neu entstehenden räumlichen Bildern Schritt für Schritt zur Lösung des Rätsels. Die Ergebnisse sind inzwischen schriftlich dokumentiert; Interessierte können außerdem auf der Wissenschafts-Plattform Zenodo nachvollziehen, welche Daten für die Simulationen herangezogen und verarbeitet wurden, sie finden dort außerdem verschiedene zweidimensionale Simulationen, mit denen die Naturphänomene nachvollzogen wurden. "Wir hoffen, dass unsere Studie dazu beiträgt, die tektonischen Verhältnisse und die Erdbebendynamik genauer zu verstehen, die in ähnlichen Verwerfungszonen lokale Tsunamis begünstigen könnten", sagt Geophysiker Thomas Ulrich. Je mehr Forscher über diese Zusammenhänge verstehen, umso wirksamer werden Prognosen und Frühwarnsysteme. (vs)
Mit Sicherheit Daten
Um die Sicherheit und Bereitstellung von Daten geht es in zwei Projekten, bei denen das Leibniz-Rechenzentrum technischer Partner und Dienstleister ist: QuaSiModO, die Abkürzung für Quanten-Sichere VPN-Module und -Operationsmodi, engagiert sich im Bereich Verschlüsselungstechnik und Kryptografie und erforscht Systeme und Verfahren, wie Netzwerke, Rechenzentren und der Datenaustausch im gerade startenden Quanten-Zeitalter vor Hacker-Angriffen zu schützen sind.
Quantentechnik kann Sicherheit gefährden
Hintergrund ist die Erkenntnis, dass das neuartige Rechenmodell eines Quantencomputers alle aktuell verwendeten Verschlüsselungsverfahren wie RSA so substantiell gefährden, dass selbst Schlüsselgrößen mehrerer Giga- und Terabyte keinen ausreichenden Schutz mehr böten. Noch gibt es zwar keine marktreifen Quanten-Computer, doch überall wird mit der Technik experimentiert. In diesem Jahr gelang es Google und IBM, mit einem Quanten-Rechner eine Aufgabe zu lösen und damit zum ersten Mal die sogenannte „Quantum-Supremacy“ experimentell nachzuweisen.
Unter der Koordination der genua GmbH, Spezialist für Daten- und Cybersicherheit aus Kirchheim bei München, wird das Leibnis-Rechenzentrum zusammen mit dem Fraunhofer-Institut für Angewandte und Integrierte Sicherheit (AISEC), der Ludwig-Maximilians-Universität (LMU), dem Netzwerkspezialist ADVA daher in den nächsten drei Jahren nach besseren Verschlüsselungsmethoden fahnden. Die Basis bildet der aktuelle Standardisierungsprozess des NIST zu neuen, sogenannten Post-Quanten Algorithmen; Das Ziel sind praxistaugliche und vertrauenswürdige standardisierte Algorithmen für den Einsatz in sicheren VPNs. Beim ersten Kickoff-Meeting Ende Oktober wurde das Projekt auch in die Initiative Bavarian Quantum Computing Exchange integriert, die sich am LRZ gerade formiert und jeden zweiten Mittwochdes Monats trifft. Das Projekt QuaSiModo wird vom Bundesministerium für Bildung und Forschung gefördert und ist bis August 2022 finanziert.
Mit Daten die Medizin verbessern
Für CompBioMed kommt die finanzielle Unterstützung von der Europäischen Union und aus den Töpfen des Horizon2020 Förderprogramms für Forschung und Innovation. Das Projekt startete bereits 2016, geht jetzt in die nächste Phase und widmet sich dem Sammeln, Auswerten und Nutzen medizinischer Daten: High Performance Computing (HPC) steht dabei im Zentrum bei deren Verarbeitung. Rund 50 Partner aus Forschung, Industrie und Kliniken haben in den letzten Jahren bereits diverse Computerprogramme, Algorithmen und smarte Systeme zur Analyse und zur Visualisierung von Bild- und Statistikdaten über Krebs-, Herz- und anderen Krankheiten entwickelt und fokussieren nun darauf, dass diese den Alltag von Wissenschaftlern und Medizinern bereichern, Therapien und medizinische Versorgung verbessern helfen und so die Gesundheitssysteme nachhaltig verändern.
CompuBioMed setzt dabei in erster Linie auf Trainings, auf Information und Beratung sowie auf die Entwicklung neuer Services. Wissenschaftler und Mediziner sollen HPC-Verfahren und -Methoden kennenlernen, mit denen sie komplexe medizinische Fragen selbst angehen und eigene Datenprojekte anlegen und lösen können. Das LRZ stellt im Projekt Datenspeicher zur Verfügung und passt vorhandene Software oder Algorithmen an die spezifischen Bedürfnisse der Medizin an. (vs)
Termine, Kurse und Veranstaltungen
Standards für Schnittstellen gesucht
Der achte internationale Workshop rund um die Schnittstellen OpenCL, SYCL, Vulkan und Spir-V, namens IWOCL, wird vom 27. bis 29. April am Leibniz-Rechenzentrum (LRZ) in Garching bei München stattfinden. Computerspezialisten und Ingenieure, die sich mit diesen Programmierschnittstellen beschäftigen, sind jetzt dazu aufgerufen, Erfahrungsberichte über die Integration dieser Schnittstellen in Supercomputing-Projekten sowie Vorschläge zu deren Erweiterung oder Standardisierung einzureichen. Die Schnittstellen beschleunigen und optimieren die Integration von Applikationen auf speziellen Prozessoren, etwa GPU oder Beschleuniger. Sie werden für die Entwicklung der nächsten Generation con High Performance-Rechnern, den Exascale-Computern wichtig, die sicher nicht mehr ohne Beschleuniger auskommen werden. Das LRZ organisiert die Veranstaltung und ist an der Auswahl der Präsentationen und Paper beteiligt.
C++ für Anfänger
Programmiersprachen wie C++ sind Tools, die Nutzern helfen, Arbeitsabläufe systematisch, logisch und konsistent zu denken und zu planen. C++ enthält viele Sprachfeatures und umfasst verschiedene Paradigmen wie präzedurale oder objektorientierte Programmierung. Dieser 5-tägige Kurs umfasst eine Einführung in die C++-Sprachfunktionen, die Paradigmenideen, den Softwareentwicklungsprozess einschließlich Programmdesign, Projektmanagement, Debugging und mehr. Die Kursteilnehmer sollten über grundlegende UNIX/Linux-Kenntnisse und Grundkenntnisse in anderen Programmiersprachen wie C, Java oder anderen objektorientierten Sprachen verfügen. Der Kurs wird von Carmen Navarrete und Martin Ohlerich in Englisch abgehalten.
Python für Anfänger
Als universell einsetzbare Programmiersprache mit wachsender Benutzerzahl wird Python von vielen Wissenschaftlern zunehmend in ihren täglichen Arbeitsabläufen eingesetzt. In diesem Kurs werden alle grundlegenden Konzepte der Programmiersprache behandelt: Funktionen, Datentypen, Bedingungen, Datenstrukturen, Objekte und Methoden, um die Teilnehmer in die Lage zu versetzen, Python für ihren täglichen Programmierbedarf zu nutzen. Der Kurs ist für Anfänger in Python und Programmierung im Allgemeinen. Dozentin Sheila Rössle-Blank. Der Kurs wird auf Englisch abgehalten.
Performance-Engineering auf Knotenebene
Dieser PRACE-Kurs behandelt Performance-Engineering-Ansätze auf der Ebene der Rechenknoten. Selbst Anwendungsentwickler, die fließend OpenMP und MPI beherrschen, haben oft keinen guten Überblick darüber, wie viel Leistung durch ihren Code bestenfalls erreicht werden kann. Denn Parallelität bringt uns nur auf halbem Weg zu guter Leistung. Noch schlimmer ist, dass langsamer serieller Code zawar gut skalierbar ist, wdabei aber oft Ressourcen verschwendet. Dieser Kurs vermittelt das notwendige Wissen, um ein tiefes Verständnis der Wechselwirkungen zwischen Software und Hardware zu entwickeln. Wir stellen die grundlegenden architektonischen Merkmale und Engpässe moderner Prozessoren und Rechenknoten vor. Pipelining, SIMD, Superskalaritäten, Caches, Speicherschnittstellen, ccNUMA, etc. werden abgedeckt. Wir zeigen auch, wie einfache Softwaretools eingesetzt werden können, um Wissen über das System zu gewinnen, Code reproduzierbar auszuführen und Hypothesen über den Ressourcenverbrauch zu validieren. Die Dozenten Professor Gehard Wellein und Georg Hager halten diesen Kurs in englischer Sprache.
Molekular-Modelle mit der Schrödinger-Suite
Experten erklären am 4. und 5. Dezember im LRZ in einem Workshop den Umgang mit der Schrödinger-Suite. Die Teilnehmenden lernen grundlegende Prinzipien und Konzepte der molekularen Modellierung mit Schwerpunkt auf der molekularen Dynamik kennen. Präsentiert werden außerdem mehrere MD-Softwarepakete und wie diese auf HPC-Systemen und dem Remote Visualization Server des LRZ funktionieren. Vorgestellt wird zudem die Schrödinger-Software-Suite, die ein breites Spektrum an Werkzeugen zur Modellierung und Berechnung von Strukturen und Eigenschaften chemischer Systeme, Antikörper und Proteine bietet. Sie umfasst Anwendungen für z.B. Quantenmechanik, Homologiemodellierung und Docking. Der Workshop richtet sich an Menschen mit grundlegendem Verständnis von molekularen Simulationen, etwa Nanowissenschaftler, Biologen, Physiker oder Forscher aus den Lebenswissenschaften.
Excel für Fortgeschrittene
Klaus Leschhorn zeigt den Teilnehmenden, wie sich mit dem wohl bekanntesten Tabellen-Programm Excel Diagramme erstellen, Daten sortieren und Tabellen bearbeiten lassen. Excel und seine Gestaltungsmöglichkeiten gehört zur Basis-Ausbildung für angehende Informatiker, der Kurs auf Deutsch steht auch den Mitarbeitenden des Leibniz-Rechenzentrums offen, die die vorhergehenden Einheiten bereits absolviert haben.
Google Cirq Bootcam
Es gibt verschiedene Quantencomputersprachen, Frameworks und Toolkits mit unterschiedlichen Programmierstilen und Zielgruppen. Für die erste Generation von Quantencomputern ist Google Cirq möglicherweise das am stärksten auf NISQ fokussierte Framework: Physiker und Informatiker können damit kontrollieren, wie Berechnungen ausgeführt werden, und das Framework an spezifische Fähigkeiten oder Architekturen anpassen. Cirq wird außerdem die Schnittstelle zur Google Cloud-Maschine sein. Teilnehmende dieses ersten Kurses zu Cirq am 16. Dezember werden in die diversen Funktionen eingeführt, Google-Dozent Alexandru Paler hält das Bootcamp auf Englisch. Mehr Informationen zum Bootcamp auf der Google-Seite.
Technik: Gebrauchtes zu Verschenken
Das LRZ trennt sich von gebrauchten Druckern. Studierende, DozentInnen oder Mitarbeitende der Hochschulen und Behörden melden ihr Interesse bis 25. November 2019 unter der Mailadresse <althardware@lrz.de> an. Wir nehmen gerne Kontakt mit Ihnen auf.
Geräte zum Verschenken:
- 2 Drucker Xerox Phaser 5500 DTM, Baujahr 2006
- 1 Drucker Xerox Phaser 7400, Baujahr 2006
Stellenangebote / Job Opportunities
Das Leibniz-Rechenzentrum sucht regelmäßig Computer-Spezialisten, Mitarbeitende oder studentische Hilfskräfte oder auch Praktikanten. Informieren Sie sich gerne auf den Karriere-Seiten des Rechenzentrums nach Ihren neuen Chancen. Zurzeit sind am LRZ folgende Stellen offen:
- IT-SpezialistIn für Informatik und E-Health
- Wissenschafliche MitarbeiterIn mit dem Schwerpunkt Virtual reality
- SachbearbeiterIn für den Bereich Steuern
- Studentische Hilfskraft: Web-Frontend-Entwicklung
- Studentische Hilfskraft im Bereich Human Resources
- Initiativbewerbungen
Sie finden alle aktuellen Stellenangebote des LRZ immer auf unser Webseite www.lrz.de/wir/stellen/.
Mehr Lesestoff
Hier finden Sie die Links zu den aktuellen Informationen aus der Supercpomputing-Community und von unseren Kooperationspartnern:
- Publikationen des Gauss Centre for Supercomputing (GCS): GSCnews 25/2019, InSIDE Autumn 2019
- Infobriefe der Gauß-Allianz: November 2019 (PDF)
- PRACE: Newsletter
Informationen zum LRZ-Newsletter
- Der LRZ-Newsletter wird in deutscher und englischer Sprache produziert. Sie finden die neuesten Ausgaben auf der Website untereinander. Schwierigkeiten bei der Darstellung? Sollten Sie den Newsletter nicht gut lesen können, schicken Sie bitte eine kurze Beschreibung des Problems an <NewsletterRedaktion_AT_lrz.de>. Vielen Dank.
- Sie können den LRZ-Newsletter über unsere Webseite bestellen oder abbestellen.
- Frühere Ausgaben des LRZ-Newsletters finden Sie im Archiv.
Impressum
- Herausgeber:
- Leibniz-Rechenzentrum der Bayerischen Akademie der Wissenschaften
- Anschrift:
- Leibniz-Rechenzentrum der Bayerischen Akademie der Wissenschaften
Boltzmannstraße 1
D-85748 Garching - Telefon:
- +49-89-35831-8000
- Telefax:
- +49-89-35831-9700
- E-Mail:
- lrzpost_AT_lrz.de
- Redaktion:
- PR-Team